最简单的字符识别方法,你知道吗??提到字符识别,大家最为熟悉的无疑是车牌自动识别和手写输入,这是字符识别的两种典型方式。
车牌是对摄像头获取的字符图片进行识别,手写输入则是多了输入回显的功能,而且需要识别的字符也会更为不规范。
字符识别属于模式识别的一类,有许多不同的方法,要想做好都不容易,这里我讲一种非常简单的识别方法,供大家对字符识别技术的学习做个参考。
该方法是以前领导告诉我的,具体来历不明,如果涉及知识产权请所有人与我联系。
开始介绍方法前先要提两个名词:相似性和归一化。
兄弟两个人的外貌,看上去比较象,就是相似性,大致一看是比较象,但细看就会发现有一些细微的不同,人对外貌进行识别也是利用相似性来进行判断,当大脑认为现在看到的人和记忆中的模样相似性达到一定尺度后就会认为是同一个人,这样就在生活中容易形成认错人的尴尬。
归一化是计算机利用相似性进行比较的一种预处理方法,比如现在画了一个人的素描像,计算机得到的图像信息就是一些线条,假如现在将素描复印两份,一份保持原尺寸,一份放大一倍,计算机对比原尺寸复印的线条会得出完全一样的结果,也就是相似性100%,但放大一倍的得到的结果刚好相反,相似性会非常低,如果预先作归一化处理,就会得到完全不同的结果,将放大一倍的素描图缩小一倍,此时计算机得到相似性100%的结果。
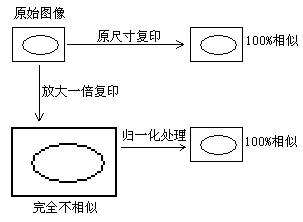
图一 归一化处理示意图
我们来看计算机如何进行相似性比较,这里用最简单的方法,就是两个图片左上角第一个点对齐,然后看整个图片有多少点一致。如果我们不考虑图像的旋转这些因素,显然原始尺寸复印出的图像和原始图像的点完全一致,相似性100%,放大一倍复印的结果则不一样,大部分点都不同,这种处理方法得到的相似性非常低。
但我们人眼一看就知道后面一种情况是放大复印的结果,两者实际上是同一幅图,看来这样处理有问题。
对于放大后图像相似性低的结果不用着急,归一化就是应付这种情况的,现在我们再加入一个处理,除了找出图像左上角的第一个基准点,我们还要找出图像最左和最右的X轴坐标值,两者相减就是图像的宽度,我们把图像的宽度处理成一致后看看是什么结果。
原尺寸复印的图像宽度自然是和原始图像一致,不用再做处理,放大的图像宽度为原始图像的两倍,需要我们做归一化处理,其实很简单,就是将放大后的图像反向压缩到与原始图像一样的宽度,这次相似性比较两种复印的图像相似性都是100%,达到我们的预期。
实际中的相似性比较和归一化处理远比我说的复杂,不过一点可以确认,基本原理一致。前面我们是用图像点是否一致来做相似性比较,这种处理方法并不适合实际应用,如果图像复印的时候稍微有一点旋转或变形,就可能得出截然不同的比较结果。
实际中用得最多的是依据特征值进行比较,先统计分析需要识别的对象的各种规律,依照规律提取特征,再由特征进行判别。
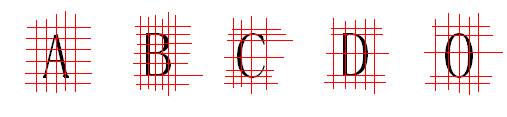
图二 字符特征值提取示意图
这是我要推介的字符简单特征值识别法,为进一步简化说明以便理解,我用几个打印的英文字母来进行示例。我们顺着图二中线来看字符,如果点为白色记为0,黑色记为1,连续相邻的多个0和1合并为一个。对于字母A我们竖向得到0、010、01010、010、0这样的特征值,横向为0、010、01010、010、01010、0。
B为0、010、01010、010、01010、010、0和0、010、0101010、010101010、01010、0。
C为0、010、01010、010、01010、010、0和0、010、01010、0。
D为0、010、01010、010、0和0、010、01010、010、0。
O为0、010、01010、010、0和0、010、01010、010、0。
我们利用这些特征值就有识别出这几个字母的可能,只是要留意D和O的特征值相同,单纯的利用特征值还不能区分这两个字母。
这就需要用户自己人为选择是D还是O,或者还需要提取一些辅助参考的特征值,接着来看D和O的不同,D的最左边明显是一条长竖线,从0个点位黑色一下就变为多个点为黑色,但O不同,黑色的点是逐渐增多的,利用这一点就能区分D和O。
实际情况远比我说的复杂,首先字符的个数要多得多,其次是镜头获取的图像不可能有图二中字母那么理想,会有漏点、扭曲、旋转等现象,如果是严格按照前面的特征值进行判断,显然绝大多数情况都识别不到。
这就要求我们适度将特征值模糊,用相似性的高低作为判定依据,在相似性不是足够高或者有多个字符相似性接近的时候引入辅助特征值。
看一下字符有哪些辅助特征值可以用到,前面说到的点与线的区别是一种。
我们还可以利用字符中的黑线交叉位置的夹角大小,比如A有3个锐角和2个钝角,B有4个近似直角和1个近似锐角,D有两个近似直角,C和O没有夹角。
利用夹角存在的特征值可以让字符的识别率大为提高,尤其是对字符的旋转有着不错的效果。另外线的交叉关系也是不错的特征值,比如两线交叉、三线交叉也能有效提高识别率。
但这只限于印刷的字符,如果是手写的很有可能完全不适用。图三为手写的字母,可以看出和印刷体相比不规范的地方要多许多,再去直接套印刷体的特征值绝对不会有好的结果。这种情况需要我们对图像做更多的预处理,图三中所示不连续的地方需要补填上有效点,象A和O顶端的小缺口也需要过滤掉,如果是污渍等形成的小面积黑点也应过滤掉。预处理后的图像再去套用前面印刷体的特征值,还是能得到不错的效果。
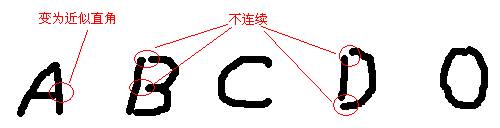
图三 不规范手写字符示意图
这里的字符识别没有强调归一化处理,因为特征值的提取和归一化联系并不紧密,但如果能在图像预处理中引入归一化处理,对识别率的提高还是有着积极意义。
象图像旋转后得到的特征值会与标准特征值有明显不同,以B为例,标准的是左边竖向为一直线,但如果B倾斜,最左边竖线就变成了点。
如果先对图像进行旋转归一化处理,还是先找到左上角的点,然后适当旋转图像,直到左边的直线变回竖立状态,注意原始图像也要进行同样的旋转归一化处理。
识别技术常会提到学习功能,学习实际上就是先拿许多样板进行处理,将样板得到的特征值存为数据库,实际识别时用被识别对象得到的特征值和数据库中的数据进行匹配,相似性最高的样板就是识别出的结果。
通常需要比较多的样板才能建立一个比较完善的数据库,就最规范的印刷体为例,镜头得到的图像有可能左倾、也有可能右倾,如果建立数据库就考虑了这三种情况,自然就更为理想。
这种简单的字符识别方法就介绍到这里,我的目的只是想让对图像识别有兴趣的朋友基本认识,通过这种简单方法初步了解图像识别,权当抛砖引玉。
汉字的识别并不是我们所想的要比英文字符复杂许多,因为英文字符笔画少,相互之间的特征值差异不大,尤其是手写,所以不好区分,笔画多的汉字相互之间的特征值差异会比较明显,区分起来反而容易。
现在汉字的手写识别多采用笔画匹配的方式,就是用点、横、竖、撇、捺的组合来匹配,当然真正写出这样的识别程序还是有一定难度,有兴趣的朋友可以在本文的基础上自己做更深入的探索字符识别方法。










 全国服务电话:
全国服务电话: